在圖像處理中,可以對圖像進行降採樣以減少像素數量,從而減少圖像的大小,而仍然保留足夠的細節以進行分析或顯示,平均池化(average pooling)和最大池化(max pooling)是實現的方法,其中又以最大池化較常見,下面簡單介紹一下執行的過程。
【池化層沒有參數、池化層沒有參數、池化層沒有參數】
設定池化窗口大小: 池化窗口是一個固定大小的矩形區域,它在輸入特徵圖上滑動。通常,池化窗口的大小是正方形的,例如 2x2 或 3x3。
滑動池化窗口: 池化窗口以一定的步長(stride)在輸入特徵圖上滑動,步長通常是1或2。步長決定了池化操作的輸出尺寸。
提取窗口內的最大值: 在每個池化窗口位置,最大池化操作將窗口內的數據取最大值。這意味著在每個窗口中選擇窗口內最亮的像素或特徵。
生成輸出特徵圖: 每次提取最大值後,將其放入輸出特徵圖的對應位置。這樣,逐步滑動池化窗口直到覆蓋整個輸入特徵圖,最終生成輸出特徵圖。
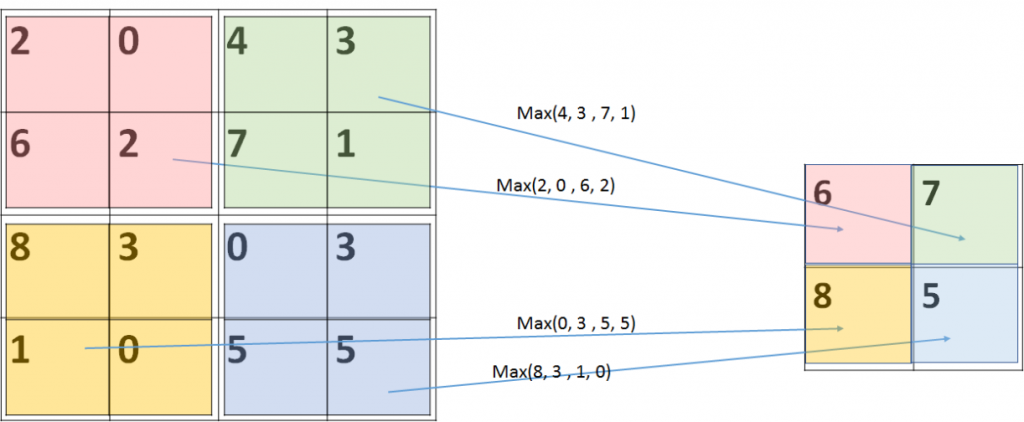
由上圖可以看的出來,過程是對原圖取最大值,因此這個池化層是模型是沒有參數的。用 Pytorch 實現的方法如下:
pool = nn.MaxPool2d(2) # 池化區設定為 2
output = pool(img.unsqueeze(0))
print(img.unsqueeze(0).shape, output.shape)
可以發現圖片的長寬小了一倍。
今天介紹了降採樣的實現方法最大池化,好處是可以縮減運算量的同時保留特徵,明天會再嘗試提高對於貓咪與兔子分類的準確度。


 iThome鐵人賽
iThome鐵人賽